- Bag of Words: cada palabra constituye una posición de un vector y el valor corresponde con el nº de veces que ha aparecido.
- N-gramas o frases: permite tener en cuenta el orden de las palabras. Trata mejor frases negativas “... excepto ...”, “... pero no...”, que tomarían en otro caso las palabras que le siguen como relevantes.
- Representación relacional (primer orden): permite detectar patrones más complejos (si la palabra X está a la izquierda de la palabra Y en la misma frase...).
Sea cual sea la representación a utilizar, es necesario indexar el documento, vale decir, representaciones compactas de él. El tipo de indexación dependerá de cual represente mejor las unidades de texto (semántica léxica) y las reglas del lenguaje natural (semántivca composicional).
Normalmente se utiliza para la representación un vector de pesos de los términos,
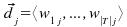
donde cada posición representa una característica del documento y contiene el peso que en el documento específico se asigna a la característica. Este peso viene dado por un valor normalmente entre 0 y 1. T representa el conjunto de características que está presente al menos una vez en el documento.
Los términos normalmente son palabras, en cuyo caso estamos ante un bag of words, pero también podría ser algo más complejo como se vió arriba. Del mismo modo, el peso puede ser binario, el término está o no presente; o un valor entre 0 y 1, para representar, por ejemplo, el peso relativo de la palabra en el documento. Todo depende del algoritmo usado.
La verdad es que, por ejemplo en [Sebastiani 2002], hay numerosa literatura que habla de que representaciones más complejas que bag of words; como podrían ser frases, tanto sintácticas (de acuerdo a la gramática del idioma) como estadísticas (que no es gramatical, sólo una secuencia de palabras), no han demostrado ser más efectivas. Esto dado que las frases, si bien tienen mejores características semánticas, tienen menores características estadísticas que las palabras solas, por la existencia de sinónimos, entre otros problemas del lenguaje, y la menor frecuencia en los documentos. [Sebastiani et al.] también aclaran que una mezcla de frases y palabras sueltas da mejor resultado, aunque esto es objeto aún de estudio.
Cuando se trata de pesos no binarios, normalmente se calcula una frecuencia de aparición del término en el documento. La ecuación de abajo es el ejemplo más común de estas ecuaciones:
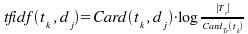
donde Card() representa la cantidad de veces que el término aparece en el documento.
Esta ecuación muestra que:
- a mayor ocurrencia del término en el documento, es más representativo del contenido
- mientras mayor sea la cantidad de documentos que contengan el término, éste es menos discriminador.
- al igual que muchas otras ecuaciones equivalentes, el orden de aparición del término ni la sintaxis de él, no reviste importancia.
Para que los pesos pertenezcan al rango entre 0 y 1, normalmente son normalizados por el coseno de normalización:
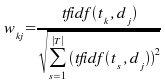
Existen otras técnicas de indexación, como probabilísticas o documentación estructurada, necesarias, por ejemplo, cuando Tr no está disponible y la cardinalidad del término no se puede calcular.
Antes de indexar, se eliminan las palabras neutras, aunque es controversial respecto de la procedencia (stemming), vale decir, agrupar palabras que comparten la misma raíz morfológica; dado que se han reportado casos donde ha sido perjudicial a la efectividad.
Dependiendo de la aplicación, se indexa todo el texto o sólo parte de él, como con los documentos estructurados.
La aproximación de indexación Darmstadt
El proyecto AIR (AIR/X) es uno de los más importantes esfuerzos en Categorización de Textos. Duró más de 10 años y desde 1985 es usado en clasificación de literatura científica, y cuenta del orden de O(105) documentos, agrupados en el orden de O(104) categorías.
La indexación utilizada en ese proyecto fue DIA (Darmstad Indexing Approach), que usa un vocabulario controlado pero ampliado con características o propiedades para los términos, documentos, categorías y relaciones entre estos. Por ejemplo:
- Propiedades de un término tk: por ejemplo, idf para tk
- Propiedades de una relación entre un término tk y un documento dj: por ejemplo, el tf para tk en dj; o la ubicación (título, resumen, etc.) de tk en dj.
- Propiedades para un documento dj: por ejemplo, el largo del documento.
- Propiedades de una categoría ci: por ejemplo, la generalidad para el conjunto de prueba de la categoría
Para cada posible relación documento-categoría, existe un “vector descriptor de relevancia” rd(dj, ci) que reúne las características de la relación. El tamaño de este vector es determinado por el número de propiedades consideradas y es independiente de la cantidad de términos, categorías o documentos.
La relación entre término y categoría se obtiene del conjunto de entrenamiento y se expresa como una probabilidad P(ci|tk) de que el documento pertenezca a la categoría ci (DIA association factor)
Esta indexación no ha sido usada para otras investigaciones, pero cobra y aumenta importancia en indexación de documentos estructurados y páginas web.

No hay comentarios.:
Publicar un comentario