Como se comentó en la presentación de este blog, lo aquí publicado no es más que lo que se ha ido recolectando respecto de Categorización de Textos.
Al respecto, se recomienda el excelente trabajo de Fabrizio Sebastiani, el que sin duda será muy educativo.
[Sebastiani, 2002] Fabrizio Sebastiani, 2002. Machine Learning in Automated Text Categorization, Consiglio Nazionale delle Ricerche, Italy. Revisado por última vez el 30 de agosto de 2005 en la URL www.math.unipd.it/~fabseb60/Publications/ACMCS02.pdf
Los siguientes papers tratan sobre Poesía y Hermes, dos aplicaciones libres basadas en Máquinas de Aprendizaje
[Gomez, Puertas, de Buenaga, Carrero, 2002] Gómez, José María y Puertas, Enrique y de Buenaga, Manuel y Carrero, Francisco, 2002. Text filtering at POESIA: a new Internet content filtering tool for educational environments. Última revisión en 30 de Agosto de 2005 en la dirección www.esi.uem.es/~jmgomez/papers/sepln02.pdf
[Gomez, Giraldez, de Buenaga, 2004] Gómez, José M. y Giráldez, Ignacio y de Buenaga, Manuel, 2004. Text Categorization for Internet Content Filtering. Última revisión en 30 de agosto de 2005 en la dirección http://tornado.dia.fi.upm.es/caepia/numeros/22/raepiaF09.pdf
La categorización de textos es considerada parte de la minería de textos. El siguiente documento da fé de ello.
[Hernandez, 2005] Hernandez Orallo, José, 2005. Web Mining, Universidad Politécnica de Valencia. Última revisión en 09 de Septiembre de 2005 en la dirección http://bbdd.escet.urjc.es/documentos/Master%20Ingenieria%20del%20Software%20DSIC%20Mineria%20de%20datos/dm4.pdf
Elsiguiente documento trata del problema del vocabulario en la comunicación.
[Furnas, Landauer, Gomez, Dumais, 1999] Furnas, G.W. y Landauer, T.K. y Gomez, L.M. y Dumais, S.T., 1999. The Vocabulary Problem in Human-System Communication: an Analysis and a Solution, Bell Communications Reseach. Última revisión en 13 de Septiembre de 2005 en la dirección http://www.google.cl/url?sa=t&ct=res&cd=3&url=http%3A//www.si.umich.edu/%7Efurnas/Papers/vocab.paper.pdf&ei=15UnQ6WxN7mI4QHz5rWCBw
[Yang, 1999] Yang, Yiming y Liu, Xin, 1999. A re-examination of text categorization methods. School of Computer Science, Carneie Mellon University. Última revisión en 25 de Noviembre en la dirección http://citeseer.ist.psu.edu/rd/0%2C361822%2C1%2C0.25%2CDownload/http://citeseer.ist.psu.edu/cache/papers/cs/5062/http:zSzzSzwww.cs.cmu.eduzSz%7EyimingzSzpapers.yyzSzsigir99.pdf/yang99reexamination.pdf
[Joachims, 1997] Joachims, Thorsten, 1997 .Text Categorization with Support Vector Machines: Learning with Many Relevant Features. Última revisión en 25 de Noviembre de 2005 en la dirección http://citeseer.ist.psu.edu/rd/41909118%2C553162%2C1%2C0.25%2CDownload/http://citeseer.ist.psu.edu/cache/papers/cs/26885/http:zSzzSzranger.uta.eduzSz%7EalpzSzixzSzreadingszSzSVMsforTextCategorization.pdf/joachims97text.pdf
[Medina Nieto M.A., 2001] EGRAI: Espacio Grupal con referencistas y Agentes como apoyo a la investigacion. Última revisión en 24 de Enero de 2006 en la dirección http://www.pue.udlap.mx/~tesis/msp/medina_n_ma/capitulo2.pdf
[Panessi y Bordignon, 2001] Procesamiento de Variantes Morfológicas en Búsquedas de Textos en Castellano . Walter Panessi y Fernando Raúl Alfredo Bordignon. Universidad Nacional de Luján, Departamento de Ciencias Básicas, División Estadística y Sistemas. Revisado por última vez en 08 de Marzo de 2006 en la direción http://www.tyr.unlu.edu.ar/TYR-publica/Varia-Morfo.pdf.
[Eyheramendy, Lewis y Madigan, 2001] On the Naive Bayes Model for Text Categorization. Susana Eyheramendy, David Lewis, David Madigan. Rutgers University. Revisado por última vez en 14 de Marzo de 2006 en la dirección http://www.stat.rutgers.edu/~madigan/PAPERS/susana3.pdf
viernes, noviembre 25, 2005
Clasificadores basados en ejemplos
Este tipo de clasificadores no construyen una representación explícita, pero confía en las etiquetas de los documentos de entrenamiento similares a los documentos de prueba. También se llaman lazy layer, porque posterga la decisión de cómo generalizar hasta que encuentra un nuevo caso.
Para decidir si dj pertenece a la categoría ci, mira si hay k documentos similares que pertenezcan a ci. Si la porción de coincidentes es alta, se toma la decisión. En otro caso, se decide que el documento no pertenece a la clase.
La similaridad se mide en relación a la distancia de los pesos. Se puede utilizar CSVi(dj) para determinar la distancia de los documentos y el método de los umbrales para convertir la decisión en una categorización binaria.
La construcción del clasificador involucra determinar k experimentalmente en el conjunto de prueba. Se ha propuesto 20 ó entre 30 y 45 documentos para una mayor efectividad. Al aumentar k no se afecta mayormente la performance.
Un caso de esta metodología es k-NN (k-Nearest Neighbors ─ los k vecinos más cercanos), que ha sido estudiada intensamente por más de cuatro décadas [Yang, 1999]. Ha sido aplicada a la categorización de textos desde las primeras investigaciones y está clasificado como uno de los métodos con mejor rendimiento para este tipo de aplicaciones. No divide el espacio de documentos linealmente, por lo que no sufre los problemas de los clasificadores lineales.
Su algoritmo es simple: dado un documento de prueba, busca los k vecim¡nos más cercanos entre los documentos de entrenamiento, y usa las categorías de estos k vecinos para determinar las categorías candidatas, construyendo un ranking de categorías dependiendo de la cantidad de documentos que compartan esta misma clasificación.
Normalmente los clasificadores basados en ejemplos usan pivote en el documento.
Este clasificador es absolutamente efectivo [Sebastiani, 2002], aunque tiene el inconveniente del tiempo que se requiere en el proceso.
Para decidir si dj pertenece a la categoría ci, mira si hay k documentos similares que pertenezcan a ci. Si la porción de coincidentes es alta, se toma la decisión. En otro caso, se decide que el documento no pertenece a la clase.
La similaridad se mide en relación a la distancia de los pesos. Se puede utilizar CSVi(dj) para determinar la distancia de los documentos y el método de los umbrales para convertir la decisión en una categorización binaria.
La construcción del clasificador involucra determinar k experimentalmente en el conjunto de prueba. Se ha propuesto 20 ó entre 30 y 45 documentos para una mayor efectividad. Al aumentar k no se afecta mayormente la performance.
Un caso de esta metodología es k-NN (k-Nearest Neighbors ─ los k vecinos más cercanos), que ha sido estudiada intensamente por más de cuatro décadas [Yang, 1999]. Ha sido aplicada a la categorización de textos desde las primeras investigaciones y está clasificado como uno de los métodos con mejor rendimiento para este tipo de aplicaciones. No divide el espacio de documentos linealmente, por lo que no sufre los problemas de los clasificadores lineales.
Su algoritmo es simple: dado un documento de prueba, busca los k vecim¡nos más cercanos entre los documentos de entrenamiento, y usa las categorías de estos k vecinos para determinar las categorías candidatas, construyendo un ranking de categorías dependiendo de la cantidad de documentos que compartan esta misma clasificación.

Normalmente los clasificadores basados en ejemplos usan pivote en el documento.
Este clasificador es absolutamente efectivo [Sebastiani, 2002], aunque tiene el inconveniente del tiempo que se requiere en el proceso.
Redes Neuronales - NNet

Las redes neuronales también han sido utilizadas en la construcción de clasificadores.
Una red neuronal es una red donde la entrada son los términos y la salida la o las categorías de interés. Los pesos representan las relaciones de dependencia. Normalmente se representan como grafos, donde los nodos representan la suma de las entradas, las flechas representan las entradas y salidas de los nodos (como podría ser un término del documento), las que vienen modificadas por los pesos.
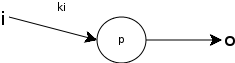
Un documento de test i, carga sus pesos de términos en las unidades de entrada de la red. La activación se propaga por la red y el valor de la salida determina la decisión de categorización.
Normalmente, se usa backpropagation,
donde las clasificaciones erróneas modifican los parámetros de la red para minimizar o eliminar el error.
La red neuronal más simple es el perceptrón, que es un clasificador lineal.
Otros clasificadores lineales de red neuronal implementan regresión logística.
Las redes neuronales no lineales son redes con una o más capas de unidades extra. En categorización de texto, normalmente representa interacciones de mayor orden entre los términos.
En general, no se notan diferencias al implementar redes neuronales lineales y no lineales.
Han sido intensamente usadas en Inteligencia Artificial [Yang, 1999] y se sabe han sido probadas con el corpus Reuter-21450, tanto con perceptrones como con Redes Neuronales de tres capas (con una capa escondida). En las experiencias se ha utilizado una red neuronal por categoría y han mostrado un alto costo computacional.
lunes, noviembre 21, 2005
Un caso interesante de Clasificador Lineal - Rocchio
El método de Rocchio:
Un caso interesante de clasificador lineal es aquel que utiliza el método de Rocchio. Básicamente, por que es fácil de implementar y, bajo ciertas condiciones, puede llegar a ser muy eficiente.
En este método, los clasificadores lineales utilizan un perfil explícito, esto es, un documento prototipo para la categoría con el cual se comparan. Son arreglos de pesos que representan un documento tipo basados en los pesos para cada atributo ci. Esta característica propicia que sea fácilmente interpretable por humanos.
El método calcula un clasificador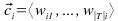
para la categoría ci,
donde

,
 ,
,

y
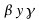
son los parámetros de importancia asignados a los ejemplos positivos y negativos.
Como se observa en las ecuaciones, básicamente calcula promedios de pesos, motivo por el que se justifica su eficiencia.
Pero al referirnos a la efectividad, tiene problemas con agrupaciones disjuntas de documentos

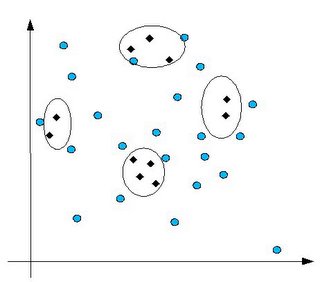
Como en el caso de la figura, el clasificador podría cometer grandes errores si el centroide no coincide con ningún documento.
Los clasificadores lineales pecan de este inconveniente precisamente porque dividen el espacio de documentos linealmente.
Mejoras al método de Rocchio
Una mejora que se puede intentar para el método de Rocchio, al crear el clasificador, es modificar el conjunto de valores negativos NEGAi. La propuesta apunta a escoger los valores que perteneceran al conjunto NEGAi, que ahora se llamará NPOSi (no positivos), y que contendrá aquellos documentos que son más cercanos a los positivos, si se quiere, los menos negativos.
Con esta modificación, la fórmula del modelo queda como:

donde el factor:

es más significante dado que son los más difíciles de separar de los positivos.
Una forma de encontrar los “cercanos positivos” es contrarrestando el centroide de los positivos, contra un documento base de los negativos. Los con menor "distancia" más altos son los elegidos.
Un caso interesante de clasificador lineal es aquel que utiliza el método de Rocchio. Básicamente, por que es fácil de implementar y, bajo ciertas condiciones, puede llegar a ser muy eficiente.
En este método, los clasificadores lineales utilizan un perfil explícito, esto es, un documento prototipo para la categoría con el cual se comparan. Son arreglos de pesos que representan un documento tipo basados en los pesos para cada atributo ci. Esta característica propicia que sea fácilmente interpretable por humanos.
El método calcula un clasificador
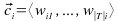
para la categoría ci,
donde
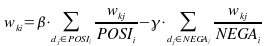
,
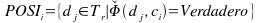 ,
,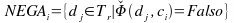
y
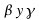
son los parámetros de importancia asignados a los ejemplos positivos y negativos.
Como se observa en las ecuaciones, básicamente calcula promedios de pesos, motivo por el que se justifica su eficiencia.
Pero al referirnos a la efectividad, tiene problemas con agrupaciones disjuntas de documentos
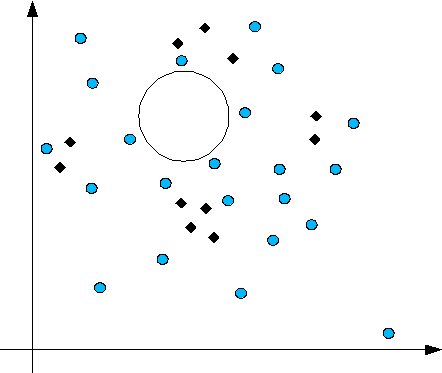
Como en el caso de la figura, el clasificador podría cometer grandes errores si el centroide no coincide con ningún documento.
Los clasificadores lineales pecan de este inconveniente precisamente porque dividen el espacio de documentos linealmente.
Mejoras al método de Rocchio
Una mejora que se puede intentar para el método de Rocchio, al crear el clasificador, es modificar el conjunto de valores negativos NEGAi. La propuesta apunta a escoger los valores que perteneceran al conjunto NEGAi, que ahora se llamará NPOSi (no positivos), y que contendrá aquellos documentos que son más cercanos a los positivos, si se quiere, los menos negativos.
Con esta modificación, la fórmula del modelo queda como:
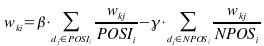
donde el factor:
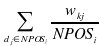
es más significante dado que son los más difíciles de separar de los positivos.
Una forma de encontrar los “cercanos positivos” es contrarrestando el centroide de los positivos, contra un documento base de los negativos. Los con menor "distancia" más altos son los elegidos.
miércoles, noviembre 09, 2005
Presentación de mi tema
Hasta ahora no he escrito nada de mi aspecto personal, pero ahora me voy a tomar la licencia porque creo que es muy importante que aprenda a partir de mi experiencia.
Si estoy estudiando y publicando lo que he ido aprendiendo, es por que siento que necesito especializarme en algo, necesito algo en lo cual yo sea realmente un experto.
Quizás por lo mismo es que decidí integrarme al plan de Magister de la Universidad de Santiago de Chile, plan del que por estos días estoy haciendo ya su tesis... indudablemente, este es mi tema de tesis.
Ayer, ante el curso de Seminario de Tesis, más algunos invitados de la misma Universidad, presenté mis investigaciones orientadas a la tesis que realizo; pero en vez de ser una experiencia agradable, creo que fue más bien frustrante, aunque muy educativa.
Ahora expongo lo que siento fueron errores que no se pueden repetir una vez que me toque hacer la presentación de mi tesis, y que espero sirva al visitante de mi blog:
Sé que muchos esperan que publique la presentación que hice (JA!... vanidad... ni siquiera sé si alguien algún día leerá esto :), por lo que aquí se las adjunto.
Agradeceré, si es que estuviste en la presentación y hay algo que aportar, que lo incorpores como comentario.
Si estoy estudiando y publicando lo que he ido aprendiendo, es por que siento que necesito especializarme en algo, necesito algo en lo cual yo sea realmente un experto.
Quizás por lo mismo es que decidí integrarme al plan de Magister de la Universidad de Santiago de Chile, plan del que por estos días estoy haciendo ya su tesis... indudablemente, este es mi tema de tesis.
Ayer, ante el curso de Seminario de Tesis, más algunos invitados de la misma Universidad, presenté mis investigaciones orientadas a la tesis que realizo; pero en vez de ser una experiencia agradable, creo que fue más bien frustrante, aunque muy educativa.
Ahora expongo lo que siento fueron errores que no se pueden repetir una vez que me toque hacer la presentación de mi tesis, y que espero sirva al visitante de mi blog:
- Incorporar elementos gráficos a la presentación: La mayor parte de los asistentes (muchos en relación a los que van normalmente a ese curso) no estaban interesados en mi tema. Noté que los escazos elementos gráficos que incorporé llamaron su atención y fueron muy didácticos a la hora de entender a lo que me refería.
- No juzgar la intencionalidad de las preguntas: Si bien la mayor parte de las preguntas me parecieron sumamente atinadas, hubo otras no tan afortunadas. Erróneamente o no, sentí que fueron hechas con mala intención, lo que me desconcentró y no me permitió seguir mi exposición en condiciones óptimas.
- No perder la paciencia: Relacionado con lo anterior, hubo un momento que ya no me interesaron las preguntas que me hizo este señor, por lo que de plano le respondí de mala manera para que no me preguntara más... craso error!!!. Además, debo intentar responder las preguntas y no caer en el debate con la audiencia.
- Dejar las preguntas para el final: El tiempo que tenía para mi exposición era limitado, sin embargo dejé que me interrumpieran durante la exposición, lo que no me parece mal, pero dadas las circunstancias, hizo que me tomara más tiempo del que realmente disponía. Debo decir al principio de la presentación que las preguntas quedan para el final.
- Colocar una diapositiva con el índice: La gente no tenía una visión global de hacia donde iba mi presentación, cosa que se podría haber solucionado con una diapositva con el índice al principio. En cierta ocasión, vi una presentación donde cada cierto tiempo se mostraba el índice con el próximo tema a tratar en otro color.
- Introducir "violentamente" al oyente al tema: Los asistentes no sabían qué iban a escuchar, por lo que demoraron un rato en involucrarse en el tema. Una diapositiva con un gráfico que explicaba lo que hablábamos y que estaba a la mitad de la presentación, debió estar al principio.
- Pulcritud de los términos: En más de alguna ocasión no utilicé el término exacto. No estoy seguro si fué una suspicacia o realmente enredé a alguien, pero me hicieron notar como un hecho grave el no haber utilizar el término exacto respecto de lo que me refería (datashow/proyector, metodología/clasificador, etc.).
- Llevar la presentación en otro formato: Se perdió tiempo importante en tener que cambiar la presentación de formato para llevarlo a otra máquina. Eso distrajo la audiencia y la predispuso a la crítica.
- Título de la exposición: El tema de la exposición debe ser tal que, con sólo leerlo, saber exactamente de qué se tratará la exposición, sin importar que quede algo largo o poco estético.
- Separar tácitamente lo que es el marco teórico de lo que era mi proyecto en sí: Si bien eso se verá ayudado con la incorporación del índice, dejar en claro cuando terminamos de hablar de la teoría y cuando ya estamos hablando de lo que voy a hacer en mi proyecto.
- Qué incluye y qué excluye el proyecto: En ningún momento me detuve y expliqué qué incluía y qué no mi proyecto. Creo que estaba claro si se revisa la totalidad de la presentación, pero la gente no estuvo siempre atenta, por lo que mucho de lo que nombré ni siquiera lo escucharon.
- Acotar el objetivo del proyecto: Sumado a lo anterior, acotar suficientemente el objetivo ayuda a definir qué incluye y excluye el proyecto.
- Definir el término del proyecto: En ningún momento hice mención clara de bajo cuales condiciones puedo dar por finalizado el trabajo.
- Referirse a lo que es y no a lo que no es: En este blog también menciono "lo que no es categorización de textos". Mala idea. La presentación siempre debe ser constructiva y no destructiva respecto del conocimiento.
- Presentación del orador y profesor guía: Algo que se me olvidó fue incluir mi nombre y el de mi profesor guía en la primera diapositiva. Eso me dará pié para presentar a mi profesor guía y a mi mismo.
- Links: Quizás más de alguien me va a decir que "nadie va a mirar los links que incluí en la presentación como referencia". Pero yo quedé con la sensación que a mi presentación le faltó eso como motivación.
- Módulo de tratamiento de textos: En mi presentación, en este blog, y en general en el proyecto que pretendo llevar a cabo con mi investigación; nunca aparece un módulo de tratamiento de textos, esto es: transformar documentos que llegan en distintos formatos (txt, xml, ps, pdf, doc, xsf, etc.) al formato que utilizará mi aplicación.
- Corregir el esquema de la solución propuesta: Me di cuenta que cuando la expuse, le faltan y sobran características... en general, el dibujo es poco preciso y hasta incorrecto.
Sé que muchos esperan que publique la presentación que hice (JA!... vanidad... ni siquiera sé si alguien algún día leerá esto :), por lo que aquí se las adjunto.
Agradeceré, si es que estuviste en la presentación y hay algo que aportar, que lo incorpores como comentario.
jueves, noviembre 03, 2005
Metodos en Linea
Un clasificador en linea para una categoría ci, es un vector
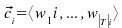
que pertenece al mismo espacio |T| dimensional en que están los documentos.
Los métodos de aprendizaje para clasificadores lineales, se dividen en:
El método lineal o incremental es recomendable cuando no se tienen todos los documentos de ejemplo en el momento; o bien, cuando el clasificador va cambiando efectivamente al transcurrir el tiempo o se espera retroalimentación de parte del usuario.
Un método en línea simple, es el perceptrón, que es la red neuronal que está compuesta por un solo nodo.
En los perceptrones, inicialmente todos los pesos para el clasificador ci son iguales y positivos. Al analizar un ejemplo, si el la clasificación resulta positiva, se incrementa el peso wki del nodo en un valor A > 0; si por el contrario, la clasificación es negativa, se disminuye en un valor A <> 0.
El perceptrón es un caso de un algoritmo de algoritmo aditivo (los pesos se modifican a partir de sumas positivas o negativas), pero también los existen de tipo multiplicativo como Ganador inmediato positivo (Positive Winnow), que es similar al perceptrón, pero en vez de sumar o restar un A, dependiendo si la clasificación es positiva o negativa respectivamente; multiplica por una A > 1 para el caso positivo, y un 0 < A < 1, en caso contrario.
Hay una variante a este clasificador, que es Ganador Balanceado. En él, se usan dos pesos para cada término, uno positivo y uno negativo (Balanced Winnow), pero el factor multiplicado es el la diferencia entre ambos.
Los clasificadores en línea usan pivote tanto en la categoría como en el documento.
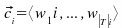
que pertenece al mismo espacio |T| dimensional en que están los documentos.
Los métodos de aprendizaje para clasificadores lineales, se dividen en:
- Batch: donde se analiza todo el conjunto de entrenamiento para construir el clasificador, como con el método de Rocchio
- Lineales o incrementales: donde se construye el clasificador al analizar el primero de los documentos, y se afina este clasificador a partir del análisis de los documentos siguientes.
El método lineal o incremental es recomendable cuando no se tienen todos los documentos de ejemplo en el momento; o bien, cuando el clasificador va cambiando efectivamente al transcurrir el tiempo o se espera retroalimentación de parte del usuario.
Un método en línea simple, es el perceptrón, que es la red neuronal que está compuesta por un solo nodo.
En los perceptrones, inicialmente todos los pesos para el clasificador ci son iguales y positivos. Al analizar un ejemplo, si el la clasificación resulta positiva, se incrementa el peso wki del nodo en un valor A > 0; si por el contrario, la clasificación es negativa, se disminuye en un valor A <> 0.
El perceptrón es un caso de un algoritmo de algoritmo aditivo (los pesos se modifican a partir de sumas positivas o negativas), pero también los existen de tipo multiplicativo como Ganador inmediato positivo (Positive Winnow), que es similar al perceptrón, pero en vez de sumar o restar un A, dependiendo si la clasificación es positiva o negativa respectivamente; multiplica por una A > 1 para el caso positivo, y un 0 < A < 1, en caso contrario.
Hay una variante a este clasificador, que es Ganador Balanceado. En él, se usan dos pesos para cada término, uno positivo y uno negativo (Balanced Winnow), pero el factor multiplicado es el la diferencia entre ambos.
Los clasificadores en línea usan pivote tanto en la categoría como en el documento.
Suscribirse a:
Entradas (Atom)
