Normalmente, se recolectan ejemplos de textos correctamente clasificados, normalmente tarea realizada por expertos humanos; los que se agrupan para servir de entrada al clasificador.
A estos ejemplos recolectados se les denomina generalmente el corpus inicial; y está definido como el conjunto O={d1,...,dn} contenidos en D preclasificados en C={c1,..., c|C|}, donde C es el conjunto de categorías existentes y D el conjunto de documentos.
A este conjunto inicial de documentos, o corpus inicial, se puede dividir de diferentes formas. Lo más normal es dividir en Entrenamiento y Prueba, donde el conjunto de entrenamiento sirve para educar al clasificador, y el de prueba para medir la efectividad conseguida. Estos conjuntos son disjuntos. Luego de probarlo, algún parámetro se moverá de modo de mejorar la efectividad del clasificador. Para ello se tiene reservado una parte del conjunto de entrenamiento no utilizado antes, que permite observar el resultado de este tunning o sintonización sobre los parámetros.
Otra manera es la Validación Cruzada. En esta variante, también conocida como k-fold cross validation; el conjunto de ejemplos conseguidos se divide en k conjuntos disjuntos, con los que iterativamente se van generando conjuntos de entrenamiento y prueba. Como el resultado será una serie de clasificadores menores, la efectidad final del clasificador está dada por el promedio de los clasificadores individuales. Al igual que el anterior, se reserva un conjunto para sintonización de los parámetros.
Se definirá Generalidad como el porcentaje de documentos del conjunto de entrenamiento que pertenecen a una categoría, de la forma como la define la siguiente fórmula:
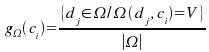

No hay comentarios.:
Publicar un comentario