La razón de querer disminuirlo es que los algoritmos más sofisticados de inducción tienen problemas para manejar vectores de gran tamaño, por eso se reduce |T|<<|T'|
Además, el reducir la dimensionalidad entrega la ventaja que disminuye el sobre ajuste, que es el fenómeno en el que el clasificador aprende las características contingentes y no sólo las constitutivas del documento.
Si bien hay muchas cifras respecto de cuánto debe ser esta reducción de dimensionalidad, llegando incluso algunos autores a proponer un 50%; la verdad es que una cifra así o superior puede llegar a ser perjudicial porque se puede llegar a eliminar términos con significado para el documento.
Respecto de los métodos de reducción, hay varios propuestos; la mayoría de ellos provienen del álgebra lineal o de la teoría de la información.
La Reducción de la Dimensionalidad puede ser vista desde dos puntos de vista:
- De modo Local: esto es, para cada categoría, es escoge |T'|<<|T| para la clasificación de la categoría (vale decir, cada categoría tendrá su propio conjunto de términos para ser evaluado). Normalmente, el valor de |T'| va de 0 a 50 términos... aunque intuitivamente se trata de cantidades empíricas.
- De modo Global: vale decir, el mismo conjunto de términos será utilizado para evaluar la clasificación en todas las categorías.
[Sebastiani 2002] nos dice que ambas formas han impactado en el resultado final, pero no se ha notado cambio cuando se trata de aprendizaje supervisado.
Respecto de cómo escoger los términos, también se ha encontrado dos formas:
- Reducción de Dimensionalidad por Selección: de los términos disponibles, se escogen los más representativos.
- Reducción de Dimensionalidad por Extracción: Los términos en T' no son los mismos que en T; por ejemplo, T' puede contener sólo palabras y T no sólo eso; pero son obtenidos por combinación o transformación de las originales.
Reducción de la dimensionalidad por Selección de Términos
También se le llama Reducción de Dimensionalidad por Espacio de Términos (TSR - Term Space Reduction).
La idea básica es que, dado un conjunto de términos T, seleccionar un subconjuto T', con |T|<<|T'|; con el que se indexan los documentos.
El TSR, ha mostrado mejorar la efectividad de la clasificación menor de un 5% dependiendo del clasificador, la agresividad de la reducción y la técnica TSR utilizada.
Dentro de las técnicas, una que debe llamar la atención es aquella llamada wrapper, que agrega y quita términos del conjunto T' inicial, para luego generar el clasificador. Una vez realizadas varias iteraciones, se selecciona aquel conjunto que presente mejores resultados. Si bien esta técnica parece ser buena, dado que a medida que aprende se afina, es prohibitiva en la mayoría de las aplicaciones de categorización de textos comunes dado el tamaño del espacio que requiere.
Frecuencia Documental
Esta es una sencilla técnica, aunque muy efectiva, donde se escogen aquellos términos que presentan mayor ocurrencia en los documentos.
Se ha demostrado (Sebastiani, 2002) que se puede disminuir la dimensionalidad del conjunto T hasta en un factor de 10 sin pérdida de información; y hasta en 100 con una pérdida de información despreciable.
Previo a la selección de los términos, y en un detalle no menor, se eliminan aquellos términos que, aportando a la redacción, no aportan información, como adverbios y preposiciones. El listado de estas palabras es almacenado en un conjunto denominado Stop Words.
A esta lista, hay quienes eliminan además aquellos términos que aparecen en un conjunto muy reducido de documentos, los que varían de 1 a 5.
Otras funciones de Teoría de Información
Nuevamente la Teoría de Información aporta a la categorización de textos; en este caso, a la reducción del espacio de términos.
Adjunto vemos un listado de las más conocidas sin perjuicio que se pueda encontrar alguna más.
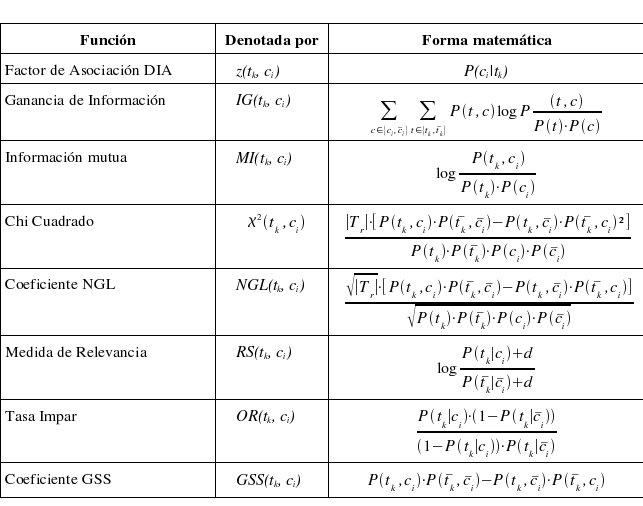
Las probabilidades son interpretadas en un espacio de eventos para los documentos, y son estimadas contando las ocurrencias en el conjunto de entrenamiento.
Todas las funciones son especificadas localmente a una categoría específica ci, con el objeto de calcular el calor para el término tk en un sentido “global”independiente de la categoría.
Lo que intentan capturar es la intuición que los mejores términos para ci son aquellos distribuidos más diferentemente en el conjunto de ejemplos positivos y negativos para ci. De este modo, las interpretaciones para este principio varían a través de las diferentes funciones.
La mayoría de las funciones de la tabla han mejorado con frecuencia de documentos.
Colectivamente, los experimentos reportados indican que en cuanto a performance que el Coeficiente NGL, Tasa impar y Coeficiente GSS, son mejores que Xi Cuadrado y Ganancia de Información; y estos, a su vez, son mejores que el resto de los restantes presentes en la tabla.
Una observación interesante que nos muestra [Sebastiani, 2002], es que Xi cuadrado y ganancia de información, han podido, con distintos corpus, reducir la dimensionalidad en un factor de 100 sin pérdida de efectividad.
Reducción de la dimensionalidad por Reducción de Términos
El objetivo es similar a la por selección de términos, vale decir, a partir de T, generar un T' donde |T'|<<|T|.
La diferencia está en que busca el aumento de la efectividad en la existencia de palabras polisémicas, hominómicas y sinonímicas.
Se llama polisemia a la capacidad que tiene una sola palabra para expresar muy distintos significados. Al igual que la homonimia, en el caso de la polisemia se asignan varios significados a un solo significante. Pero, mientras la homonimia se produce por coincidencia de los significantes de diversos signos, la polisemia se debe a la extensión del significado de un solo significante. (Fuente: Wikipedia.org)
El método, cualquiera que este sea, se basa en:
- Un método de extracción de nuevos términos a partir de los viejos
- Un método de transformación de la representación original a la nueva basado en la nueva síntesis.
Don métodos se han probado en Categorización de Textos: Agrupación de Texto (Text Clustering) y Indexación Semántica Latente (Latent Semantic Indexing – LSI).
Agrupación de Textos
Trata de agrupar palabras con alto grado de semejanza (centroide o término representativo) para ser usado como término en la dimensión del espacio vector. Trata de hallar sinonimia.
El clustering puede ser no supervisado:
i)Buscar términos semejantes por alguna medida de similaridad
ii)Buscar co-ocurrencia o co-ausencia en los documentos de entrenamiento
o supervisado:
Se agrupan aquellos términos que tienden a estar presentes en la misma categoría o grupo de categorías.
El supervisado ha presentado mejores resultados con sólo un 2% de pérdida de la efectividad con una agresividad de 1000 y mejoras al bajar la agresividad.
Los resultados con no supervisados son pobres.
Indexación Semántica Latente
Originalmente fue desarrollado para Recuperación de la Información para resolver problema de uso de sinónimos, términos similares y palabras polisémicas en representación de documentos.
Comprime vectores de documentos en vectores de menor espacio dimensional, cuyas dimensiones son obtenidas como combinación de las dimensiones originales mirando sus patrones de co-ocurrencia.
Las dimensiones obtenidas no son intuitivamente interpretables, pero trabajan bien trayendo la estructura semántica latente del vocabulario usado en el corpus.

No hay comentarios.:
Publicar un comentario