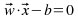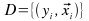Los comités de clasificadores se basan en la idea que si, para una tarea
se requiere un experto, un grupo de expertos hará igual tarea mejor.
En categorización de texto, se aplican clasificadores para decidir si dj
pertenece a ci y se combina la salida apropiadamente.
* Requiere escoger k clasificadores
* Escoger la función de combinación
Los clasificadores del comité deben ser tan independientes como se
pueda, tanto en indexación como en el método inductivo. [Sebastiani,
2002]
Respecto de la función, la más simple es “por mayoría simple”:
Otra regla que se puede aplicar es por combinación lineal de pesos;
pesos que representan la efectividad relativa que se espera del
clasificador y que se validan en el conjunto de entrenamiento.
También se puede usar Selección Dinámica, donde los clasificadores se
eligen según sea el más efectivo para un documento dj similar. Su
decisión es la que adopta el comité.
Una alternativa intermedia es someterlo al juicio de todos los
clasificadores, pero la salida ponderarla según pesos para los
clasificadores según un documento dj similar al evaluado.
Se ha experimentado con varias combinaciones, normalmente de 3
clasificadores cada uno, pero han adolecido de una baja cantidad de
documentos a clasificar, por lo que los resultados son poco concluyentes