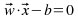
Para definir esta mejor separación, se introduce un margen entre las dos clases, y aunque se muestra el caso bi-dimensional separable linealmente en la figura, pero se puede generalizar para más dimensiones y no separable linealmente, lo que sería un hyperplano. La mejor separación, se refiere a que el margen entre la superficie que divide y los puntos se maximice.

En términos geométricos, puede ser visto como el intento de encontrar, a través de todas las superficies en el espacio |T|-dimensional, aquel que separa los negativos de los positivos, por el más amplio margen posible.
La fórmula muestra la superficie de decisión para SVM, donde x es un punto de dato arbitrario (a ser clasificado), mientras que el vector w y la constante b son aprendidas del conjunto de entrenamiento para los datos linealmente separables. Dado
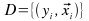
que denota el conjunto de enternemiento, y donde yi tiene valor +1 si x es un ejemplo positivo y -1 si es uno negativo; el problema se limita a encontrar w y b que satisfagan:

lo que puede ser resuelto usando técnicas de programación.
Los algoritmos para resolver casos lineales se pueden extender para resolver casos no-lineales al introducir relajaciones a los márgenes de los hiperplanos o mapeando los vectores de datos originales a un espacio de dimensionalmente mayor donde no se pierdan las características de los
datos pero sí se puedan separar linealmente.
Es notable que la mejor decisión de superficie esté determinada sólo por un pequeño conjunto de ejemplos de entrenamiento, llamado soporte vector. Con sólo este conjunto de puntos, la decisión del hiperplano escogido para separar sigue siendo la misma.
Dos importantes ventajas para categorización de textos son:
- La selección de términos frecuentemente no es necesaria, SVM tiende a ser bastante robusto al sobre ajuste y puede escalar a considerables dimensiones.
- No requiere esfuerzo en sintonizarlo en un conjunto de validación.

No hay comentarios.:
Publicar un comentario